May 25, 2026
Custom Ecommerce Development: Why the Data Layer Comes First

Chris Johnson
CEO

Most engineers starting a custom ecommerce build spend their first week deciding on a frontend framework. Next.js or Qwik. Go or Node. PostgreSQL or a document store. These are real decisions that matter. But they are also the wrong place to start.
The decisions that determine whether a custom ecommerce platform ships on time and stays maintainable are not frontend decisions. They happen one layer deeper, before you write a single product page or configure a checkout flow. They are data architecture decisions. For teams building in the appliance and furniture vertical, getting those decisions wrong is the most common reason a custom build takes twice as long as projected. This guide walks through how to approach custom ecommerce development with the data layer first, and how the Skulytics API is built specifically to be that foundational data layer for appliance, furniture, and mattress platforms.
What Custom Ecommerce Development Actually Involves
Custom ecommerce development means building a commerce platform from constituent parts rather than adopting an opinionated SaaS solution. Instead of accepting Shopify's data model or BigCommerce's checkout flow, you own the full stack. You design your database schema. You write your order management logic. You control how product data flows from suppliers through your system and out to the browser.
The appeal is real: complete control over functionality, no platform transaction fees, and the ability to build workflows SaaS platforms simply cannot support. The tradeoff is equally real. You also own every maintenance burden that a platform vendor would otherwise carry for you.
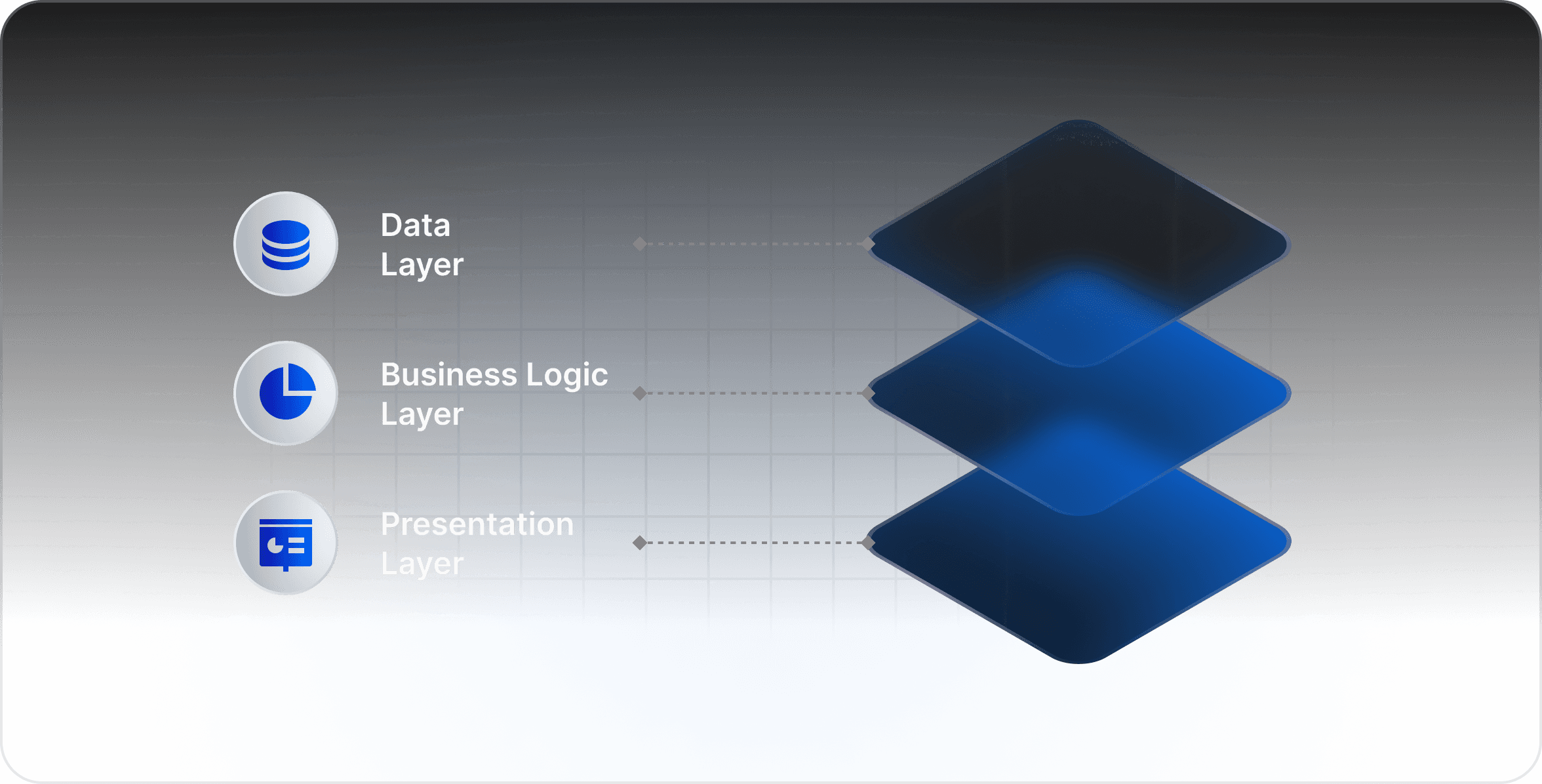
A custom ecommerce build typically involves three distinct layers:
The data layer: product catalog, inventory, pricing, supplier integrations, media
The business logic layer: cart, checkout, promotions, order management, fulfillment routing
The presentation layer: frontend, search and filtering, product detail pages, browse flows
Most teams budget and scope based on the presentation layer because that is what a stakeholder can see and react to. The data layer gets treated as a backend detail, something to wire up in the first sprint and move on from. That assumption is where projects get into trouble.
Each layer builds on the stability of the one below it. A checkout flow is only as reliable as the pricing and inventory data it reads. A search interface is only as accurate as the product attributes it indexes. A comparison feature only works if the spec fields it compares share a common schema. This dependency runs in one direction, from the data layer up. The quality of your data architecture at the start of the project sets the quality ceiling for every user-facing feature you build on top of it.
Why the Data Layer Is the Hardest Part
Building a product catalog sounds manageable until you are working with real supplier data. If your platform serves a single manufacturer that provides a well-formatted REST API with consistent JSON, the data layer is genuinely straightforward. That scenario describes almost no platform in the appliance or furniture space.
In practice, you are working with suppliers who each deliver data differently. One sends weekly CSVs with column names someone chose internally a decade ago. Another publishes an XML feed that changes structure whenever they update their internal systems. A third sends inventory updates via EDI. A fourth provides a spreadsheet by email with no automated delivery at all.
The challenge is not fetching the data. Fetching is the easy part. The challenge is normalizing it into a consistent schema your application can query reliably, then keeping that normalization working as the upstream sources drift and change. In a mid-size appliance or furniture platform supporting 50 to 100 brands, the normalization work alone can occupy an engineer full-time before the first product page ships.
The Schema Drift Problem
Consider what happens when a manufacturer changes their CSV format mid-season. Your parser breaks. The build process either fails silently or populates your catalog with malformed records. An engineer has to diagnose which field changed, update the mapping, test the fix, and deploy it. If you are managing 40 manufacturer feeds, some variation of this scenario happens multiple times per month.
The math is not abstract. A team managing 40 manufacturer feeds at 2 hours of diagnosis and remediation per feed per month is spending 80 engineer-hours monthly on data pipeline maintenance. That is two weeks of a full-time engineer's time, every month, just to keep the catalog accurate. Those hours do not go to building features. They do not go to improving search relevance or checkout conversion. They go to chasing CSV drift.
Authorization-Gated Pricing: A Problem SaaS Platforms Ignore
There is a second data layer problem that generic ecommerce platforms handle poorly: pricing is not public in this industry. Manufacturers publish MAP (minimum advertised price) floors, but actual dealer pricing is authorization-gated. A retailer sees one price. An anonymous shopper sees another. A volume dealer sees a third. Some spec sheets and technical documentation are restricted to authorized dealers entirely.
A custom platform must implement field-level authorization logic at the API layer. This is not something you can bolt on later. If your data layer returns a single price field per product, retrofitting multi-tier pricing into your frontend is a significant refactor. The authorization model needs to be part of the data architecture from week one.

The Manufacturer Data Problem in Appliance and Furniture
The appliance and furniture industry has a data problem that is structural, not accidental. Manufacturers were not organized around making data easy for retail platforms to consume. They were organized around manufacturing and distributing physical products. The data infrastructure is a side effect of their internal systems, not something maintained for external developers.
A mid-size ecommerce platform in this vertical might integrate data from 100 to 400 manufacturers. Each handles specs differently. One uses "cu. ft." for refrigerator capacity. Another uses "cubic feet." A third uses a numeric value with no unit attached. One sends image URLs. Another sends filenames that correspond to images you have to fetch from an FTP server. One updates inventory daily. Another updates weekly, on a schedule they do not publish.
The job of the data layer is to absorb all of this inconsistency and produce a uniform, queryable schema your application logic never has to think about. Your cart should not need to know which manufacturer a product came from. Your search index should not need per-brand logic to filter by capacity. Your product detail page should make one data call and get everything it needs.
Building that abstraction yourself, from raw manufacturer sources, is the longest and most unpredictable part of a custom ecommerce project. It is also the part that has the least to do with what makes your platform valuable. The value is in your user experience, your pricing strategy, your retailer relationships, your business logic. The data normalization layer is table stakes infrastructure you need to have in place before any of that becomes possible.
There is a useful framing from systems engineering: the interface contract. Your application layer needs a clean, stable interface to product data. The question is whether you build the infrastructure that fulfills that contract yourself or integrate something purpose-built for it. In a vertical where the upstream data is this fragmented and the normalization problem this well-understood, the case for the latter is strong.

What a Clean Data Layer Looks Like in Practice
The target state is straightforward to describe: a single API endpoint that returns structured JSON for any product, regardless of which manufacturer it came from.
The response includes normalized attributes (dimensions, materials, finish options, energy ratings), real-time pricing where the requesting user is authorized to see it, current inventory availability, image references in a consistent format, and any authorization-restricted spec data gated by the caller's credentials. The Skulytics API delivers exactly this structure, one REST endpoint, consistent JSON, brand-level authorization applied before the response leaves the server.
Your frontend team makes one API call. Your search indexer reads from one schema. Your ERP pulls from one source of truth. When a manufacturer updates a spec or a price, a webhook fires and your catalog reflects the change automatically. No parser to update. No cron job to monitor. No schema migration to deploy.
The benefit is not just developer time. It is application correctness. When your data layer is consistent, your faceted search filters work accurately because every product has the same attribute structure. Your comparison feature works because the spec fields are normalized. Your inventory display is reliable because availability comes from a live source, not a stale feed.
Key insight: The teams that ship custom ecommerce platforms on time are not the ones that pick the best frontend framework. They are the ones that lock down a clean, consistent data layer in the first two weeks and build everything else on top of a stable foundation.
Tech Stack Decisions That Depend on Your Data Architecture
Your data layer architecture constrains every decision above it in the stack. Worth making explicit before you start choosing frameworks.
Regardless of which backend language you use, your application needs normalized JSON you can reliably index. Inconsistent attribute fields across manufacturers make faceted filtering either impossible or require brand-specific workarounds that compound over time. The Skulytics API is a standard REST interface that works with Go, Node, Python, Ruby, or any other language without custom adapters.
If you are using a modern frontend framework like Qwik or Next.js with server-side rendering, your product pages depend on a single, fast data call. If that call is aggregating across multiple inconsistent sources at request time, your page performance suffers and your caching strategy breaks down.
If you are building a headless commerce architecture with separate frontend, catalog, and checkout services, the inter-service contract for product data needs to be stable. Any instability in the data layer propagates to every service that consumes it.
Here is a concrete illustration. Consider a two-month sprint cycle on a headless ecommerce project. If the product data schema is still shifting in month two because manufacturer feeds are inconsistent, the frontend team cannot finalize product cards, the search team cannot build reliable filters, and the checkout team cannot confirm which fields to read for pricing. One unstable data layer blocks three parallel workstreams at once.
The pattern holds across stacks. The presentation layer and business logic layer are only as good as the data layer underneath them. Decisions about headless architecture, search implementation, and real-time inventory display all have a hard dependency on clean, consistent, reliable product data.
Data layer instability also creates a team coordination problem. A UI component that renders product specs cannot be finalized until the spec schema is stable. A search filter that surfaces products by refrigerator capacity cannot be built until every product in the catalog has a normalized capacity field. The problem does not stay with the backend engineers closest to it. It cascades.

Building vs. Integrating: Where Skulytics Fits
When you are scoping a custom ecommerce build for the appliance, furniture, or mattress space, you have a choice at the data layer: build your own manufacturer integrations or integrate a purpose-built product data API.
Building your own means writing and maintaining parsers for every manufacturer you need to support. It means owning the normalization logic, the authorization rules, and the monitoring infrastructure to detect when a feed breaks. Every new manufacturer you add becomes an engineering project, not a configuration task.
Skulytics is built specifically to handle this layer. The Skulytics API delivers normalized, authorization-aware product data for 300+ appliance, furniture, and mattress brands through a single REST endpoint. Responses are structured JSON. Real-time pricing and availability updates arrive via webhooks. Field-level permissions ensure dealer-restricted data only reaches users with the right authorization level.
Your team handles the application logic, frontend, checkout, CMS, and the features that differentiate your platform. Skulytics handles manufacturer data ingestion, normalization, schema maintenance, and authorization. Customers using Skulytics have reported a 90% reduction in time spent on manual data work.
For teams evaluating the build vs. integrate decision, the cost comparison is concrete. The Skulytics Individual Plan starts at $100 per month for 100,000 API calls. The Platform Plan, designed for multi-tenant or high-volume platforms, runs $2,500 per month for 2.5 million API calls. Against the alternative of engineers spending meaningful portions of their sprint cycles on data pipeline maintenance indefinitely, the math tends to resolve itself.
Start With the Data, Then Build the Platform
The engineers who get custom ecommerce projects across the finish line are not the ones who picked the cleverest tech stack. They are the ones who made the right decision about the data layer before they wrote any application code.
For appliance and furniture platforms, that decision has a clear shape. You need a normalized product data API that handles manufacturer inconsistency, authorization-gated pricing, and real-time updates for hundreds of brands without your team maintaining any of it directly.
Skulytics gives you a 14-day free trial with 5,000 API calls. Start there. Wire up a few brands. See what your catalog looks like when the data comes back clean, consistent, and structured for a modern JSON-based application. Then build your platform on top of that foundation.
You will ship faster, maintain less, and not spend the first quarter of your project rebuilding parsers.